


JupyterLab File System
The journey of a girl through open-source software, and space.
What is JupyterLab?
JupyterLab is an open-source, browser-based interactive environment that supports a wide range of workflows in data science, scientific computing, and machine learning. The project was founded as a way for data scientists to explore, test, and share code and prose in the form of academic journals.
As Jupyter’s newest offering, JupyterLab was born of its predecessor, Jupyter Notebook, and offers a modular interface that allows for flexible use, and plugins that offer an additional degree of customization.
Team
Jana Abumeri
Emily Fan (me)
Justin Lischak Earley
Grey Patterson
Nick Straughn
Role
Design Lead
Tools
Figma
Sketch
Optimal Workshop
Duration
9 months
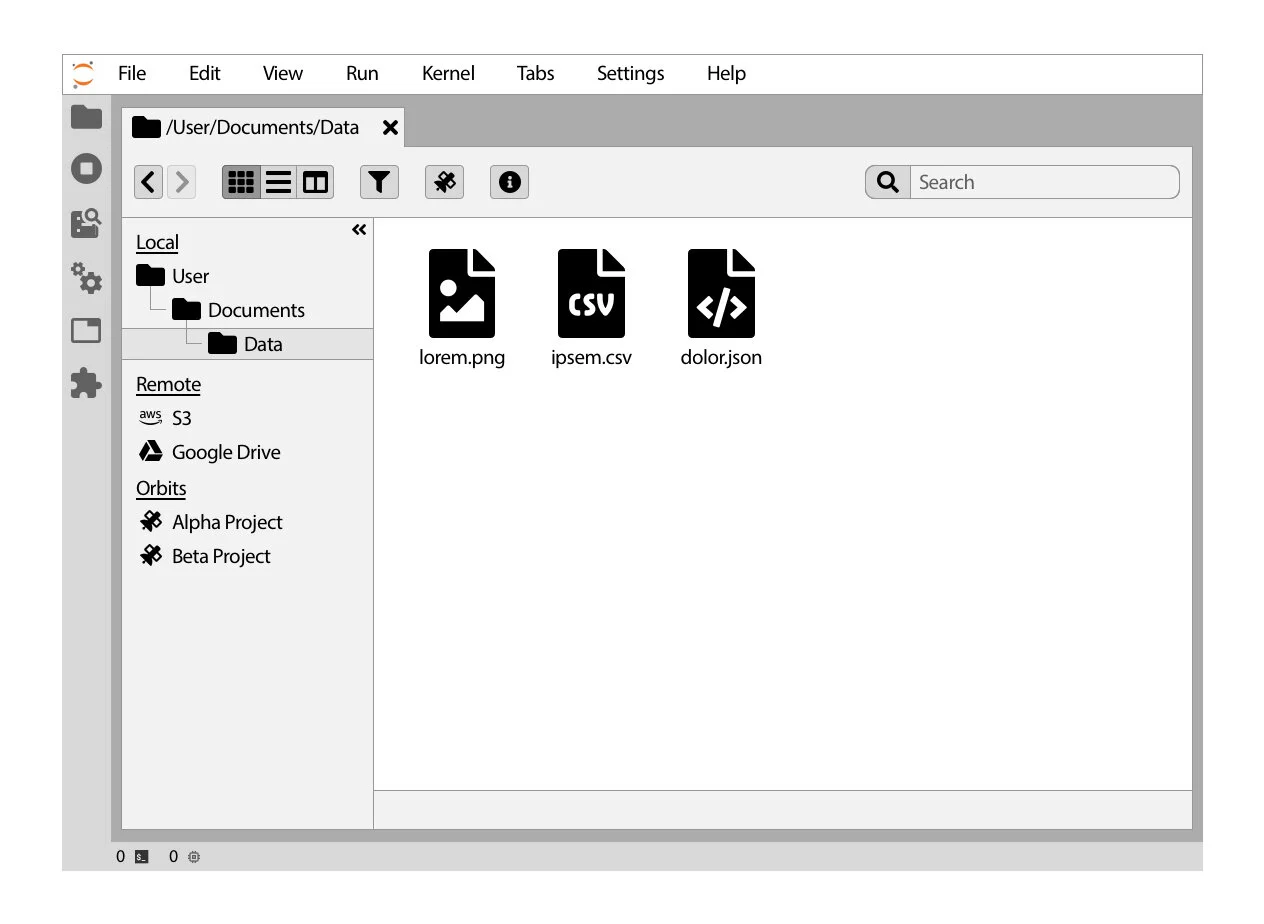
So what’s up with the file system?
“It’s difficult just to know where you are.”
In one of our early interviews with the Jupyter team, Tim Paine, a key stakeholder in the project, said it was difficult to orient yourself in the existing file browser. This is obviously problematic, as one of the fundamental pillars of organization is understanding where you and your things are. In addition to poor way-finding, the existing file browser suffers from built-in, but invisible “safety features” that prevent users from accessing locations outside the directory JupyterLab was launched in, and untimely feedback that has eroded users’ trust in existing features.
Our goal was to design a file system that supports the base actions of locating and organizing files, while implementing some of the JupyterLab community’s requested features.
Methods
Heuristic Evaluation
The team began the project by conducting a full heuristic evaluation of JupyterLab to become acquainted with this highly technical product. This was particularly challenging, as the team generally lacked developer know-how, but this was also advantageous, as we were evaluating JupyterLab from the eyes of novice users who make up a significant part of the user base.
Competitive Analysis
Once we understood what we were working with, we analyzed 9 direct and indirect competitors that occupied a similar realm as JupyterLab to understand where our competitors excelled, and to identify opportunities in the market.
Interviews + Surveys
At the heart of JupyterLab lies a strong, dedicated user base that has invested significant work and time into creating this software. Anything we designed would need approval by this group, so we spent significant time understanding the feelings and concerns of the user base. This informed the personas and journey maps that would guide our concept ideation.
Concept Ideation
With a dedicated design prompt and context-specific design criteria, we began sketching preliminary concepts. Out of those concepts, we produced two very different design directions, which we would pressure test with stakeholders and the community. These concepts were posted to the JupyterLab GitHub regularly for community input.
User Testing
Due to the short-term nature of the project, we ran our testing and design tracks simultaneously, incorporating testing insights as we received them to optimize our time. Our testing team conducted remote, unmoderated tests with a group of volunteers from the community that included a first-click test, and 2 usability tests.
Final Prototype
We’re still working on this, but check back mid-September for the final prototype!
Phase 1
Problem Setting
“…be sure that you are constantly and forever and without interruption involving the community that everything you do is going to be impacting.”
— Dr. Darren Denenberg on working in open-source
Heuristic Evaluation

Our heuristic evaluation was conducted using the Nielson Norman Group’s 10 Heuristics. We evaluated only actions that were related to the file browser, noting the heuristic violated, and the severity rating of the violation. We offered our recommendations to remedy these violations in accordance with the 10 Usability Heuristics.
Competitive Analysis

In our competitive analysis, we split our competitors into two categories: direct and indirect. Those we categorized as direct competitors were mostly IDE’s with similar code-crunching capabilities, while indirect competitors were evaluated primarily on the way they organized and handled files.
User Interviews + Surveys

Our first real contact with the JL user base was through an introductory survey. We wanted to better understand how people use the file browser as it is, what they disliked about it, and what they wanted to see next. We quickly discovered that the vast majority of those surveyed were developers or data scientists who considered themselves of mid- to expert-level proficiency.
We interviewed 10 JupyterLab users of varying expertise levels and occupations. They ranged from key stakeholders to students, and revealed three feature-level challenges:
Lack of functionality: Feature does not exist.
Lack of discoverability: Feature exists but users do not know it does.
Lack of feedback: Feature exists but users do not trust it.
From these interviews, the key quotes, pain points, and touch points would be used to craft personas and journey maps, and we were also able to extract a rudimentary feature request chart.


Personas + Journey Mapping

Our research until this point in the project had revealed that JupyterLab’s user base is diverse in both occupation and expertise. We identified 4 key personas who made up the vast majority of users: the data scientist (expert), the developer (expert), the intern (intermediate), and the student (novice).
Each user’s journey was mapped from spinning JupyterLab up, till the end of their work flow. While the journeys were highly variable, every persona had 2 common pain points: finding files, and organizing them once found. We would center our design prompt and requirements around these two points once we began the problem solving phase of the project.
Problem Setting Summary
JupyterLab’s current file browser suffers primarily from a mismatch between the user’s mental model of a file browser, and how the file browser actually works. Currently, the file browser does not differentiate between “remote” and “local” in the traditional sense. Instead, JupyterLab understand files only in relation to the “kernel” running JupyterLab, which presents itself, fundamentally, as a problem of “ceilings and bridges”:
“Ceilings”
The user is trapped in their working directory
No visibility into outer file system
No indication that there is an outer file system
“Bridges”
External tools to copy files into “local” space
GoogleDrive/GitHub/S3 plugins
Not always available – poor latency, connection failures, etc.
Phase 2
Problem Solving
Design Prompt
Design a file browser UI for JupyterLab that is recognizable, easily navigable, and offers the user transparency into where their files are located. The design should primarily support location and organization of one’s files. Seamless connectivity to other sources and data, and collaboration with peers and the community should also be considered, but are secondary to the location and organization of files.
Design Criteria
Where am I: A file’s location should be readily apparent.
Just in time: Visual cues should occur as needed, and exactly when an action occurs.
The right place: Coherent information architecture optimized around one-click actions, nested actions, right-click actions.
The right tools: Users should be given basic file management features and tools.
Concept Ideation

Exploratory sketches
Concept 1: “Mac Finder Lite”
In our competitive analysis, we noted that advanced file browsers tend to have a larger working space, while JupyterLab’s remains tethered to a thin sidebar. We began thinking about how a full-sized file browser might look in JupyterLab, and came up with a very Mac Finder inspired design. This concept would live in the JupyterLab workspace, and would allow users to apply “orbit tags” to files to informally group them.
After initial sentiment testing, we found that, while novice users found this concept very interesting, more experienced users struggled to incorporate this design into their existing mental models. However, there is potential for this concept to be developed as an extension of the sidebar file browser, and we will be handing off our supporting research and artifacts to the JupyterLab team for future development.

Multi-browser capability

Creation of “Orbits”

Concept 2: Launcher Add-On
Our second concept would leave the file browser in the sidebar, but add a Launcher-type extension to the UI that would act as a manager for a new feature called “Spaces”.
We repeatedly heard from our interviewees that they could be working with a dozen data files in a single notebook, and would appreciate a way to easily access all the files they need in a project. Workspaces were a concept that already existed in JupyterLab, but there was no visual way to manage the files you placed in a workspace. Remote connections shared a similar problem. The implementation of “spaces” would give users a way to interface with the files they placed in workspaces while organizing projects for easy access and handoff.
Initial sentiment tests revealed that this concept was much more in line with the advanced users’ mental model, and would be less developmentally taxing to implement, so we chose to proceed with this concept for this project.

Closer look at space creation and spaces in context
Prototyping
Lo-Fi Prototype


Mid-Fi Prototype


User Testing

Round 1: First Click Test - 70 Testers
Coming out of our research phase, we had a qualified set of feature requests that fell into one of three categories:
1. Feature exists but is not discoverable to the user,
2. Feature exists but does not match the user’s mental model, and
3. Feature does not exist within the current JupyterLab build.
Armed with this knowledge and a list of requested features, we set out to establish an information architecture. We settled on a MacGyvered first-click test through OptimalSort in hopes of answering the question “Where would you go to initiate this action?”
Testers were given an action item, and instructed to click the geospatial location they would think to look for that action. With these test results, we were able to transition from sketches to data-driven wireframes.
Final Prototype
Coming soon!
Challenges
JupyterLab is a highly technical product…
I’m not a developer, and neither is (most of) my team. We had to be walked through the installation and launch of JupyterLab, not even mentioning using it. It’s a powerful and complicated tool, but understanding it is its own reward.
…with a highly technical user base.
JupyterLab is the product of countless hours of work generously donated by a very talented and dedicated group of developers, designers, and analysts. Not only are these folks highly intelligent, JupyterLab is a direct result of their contributions. We made sure to always keep that in mind, and remain respectful of the community that built the platform we were standing on.
It’s open-source.
Anyone who has never worked on an open-source project should try it sometime. It’s humbling, frustrating, and extremely rewarding all at the same time.
The world is in a pandemic.
I left this point to be made until the very end for a couple reasons. First, my Master’s program at UCI is considered “low residency” in that the majority of our curriculum is conducted in a remote setting. I felt relatively adequately prepared to carry out our capstone project remotely, and I attribute that to the leadership of my professors and program director. Second, it’s not exactly a secret that many organizations are either fully remote or were toying with the idea pre-pandemic. To think that UX would be practiced at a distance in the not-so-distant future isn’t an absurd thought. However, the challenge here was the unprecedented mental toll that COVID-19 would have on the world, my team included. There have certainly been struggles, and there will definitely be more struggles, but I could not have wished for a more supportive, hard-working team if I tried. To my team, I can only say: thank you.